공공 의료데이터 상세

응급실 임상 대화 데이터
데이터 변경이력
| 버전 | 일자 | 변경내용 | 비고 |
|---|---|---|---|
| 1.1 | 2023-11-10 | 데이터 최종 개방 | |
| 1.0 | 2023-05-26 | 데이터 개방 | Beta Version |
데이터 히스토리
| 일자 | 변경내용 | 비고 |
|---|---|---|
| 2025-09-05 | 데이터셋 변경 | 구축업체정보 수정 |
| 2025-05-08 | 데이터셋 변경 | 구축업체정보 수정 |
| 2025-01-06 | 데이터셋 변경 | 메타데이터 데이터 구축량 정보 수정 |
| 2023-12-20 | 산출물 공개 | 산출물 최종 공개 |
소개
응급실에서 의료진과 환자 간의 진료 대화를 4가지 진료프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실)으로 구분하여 녹음한 음성데이터
구축목적
응급실에서 의료진과 환자 간의 진료 대화를 비식별화하여 음성인식 및 진료 프로세스를 구분하여 AI 활용 모델을 만들기 위한 목적으로 구축
| 데이터 영역 | 헬스케어 | 데이터 유형 | 오디오 |
|---|---|---|---|
| 데이터 형식 | WAV | 데이터 출처 | 고려대학교 구로병원 응급실, 고려대학교 안산병원 응급실, 고려대학교 안암병원 응급실 |
| 라벨링 유형 | 전사(음성) | 라벨링 형식 | JSON |
| 데이터 활용 서비스 | 응급실 진료 음성인식 서비스, 진료 분류 서비스 | 데이터 구축년도/ 데이터 구축량 |
2022년/5,352 |
데이터 통계
1) 데이터 구축 규모
| 데이터 종류 | 데이터 항목 | 데이터 형식 | 카테고리 분류 | 데이터 수 |
|---|---|---|---|---|
| 응급실 임상 대화 데이터 | 원천 데이터 | WAV | 예진 | 1,049건 |
| 초진 | 1,431건 | |||
| 투약 및 검사 | 1,646건 | |||
| 검사결과설명 | 1,118건 | |||
| 및 퇴실 | ||||
| 합계 | 5,244 | |||
| 라벨링 데이터 | JSON | 예진 | 1,049건 | |
| 초진 | 1,431건 | |||
| 투약 및 검사 | 1,646건 | |||
| 검사결과설명 | 1,118건 | |||
| 및 퇴실 | ||||
| 합계 | 5,244 |
2) 데이터 분포
가. 중증도 분포
| 카테고리 구분 | 데이터 수 | 비율 |
|---|---|---|
| KTAS 3 (응급) | 4,188건 | 79.86% |
| KTAS 4 (준응급) | 823건 | 15.69% |
| KTAS 5 (비응급) | 233건 | 4.44% |
| 합계 | 5,244건 | 100% |
나. 질병 분포
| 카테고리 구분 | 데이터 수 | 비율 |
|---|---|---|
| 질병 | 4,253건 | 81.10% |
| 질병 외 | 991건 | 18.90% |
| 합계 | 5,244건 | 100% |
다. 성별
| 카테고리 구분 | 비율 |
|---|---|
| 남성 | 47.85% |
| 여성 | 52.15% |
| 합계 | 100% |
라. 연령대
| 카테고리 구분 | 비율 |
|---|---|
| 20대 | 9.65% |
| 30대 | 9.21% |
| 40대 | 9.53% |
| 50대 | 17.66% |
| 60대 | 19.43% |
| 70대 이상 | 34.52% |
마. 발화 시간
| 카테고리 구분 | 비율 |
|---|---|
| 의료진 | 63.05% |
| 환자 | 25.18% |
| 보호자 | 11.77% |
활용 모델
1) 음성 인식 모델
● 모델 학습
Librosa를 통해 수집된 음성 데이터를 학습모델에 사용할 수 있도록 20초 미만의 음성으로 slicing을 통해 전처리 수행
전처리된 음성 데이터를 OpenAI사의 Whisper모델에 Transfer Learning(전이학습) 하여 소음이 포함된 응급실 임상 대화를 인식하는 음성 인식 모델을 개발
| 학습 | 검증 | 시험 | |
|---|---|---|---|
| 개요 | OpenAI Whisper 학습 | 학습 도중 모델 성과 평가 및 비교 | 모델 학습 완료 후 모델 테스트 |
| CER 점수 등 | |||
| 학습 데이터 | 4195례 | 525례 | 524례 |
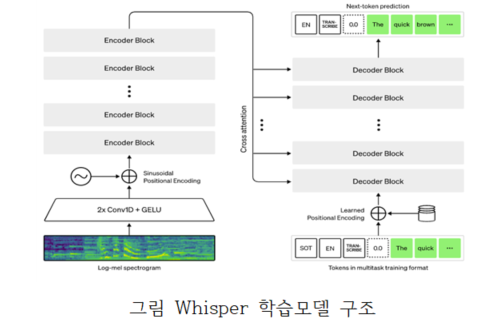
● 서비스 활용 시나리오
구축한 모델은 응급실에서 발생하는 의료진-환자 간의 대화를 인식하는 서비스에 활용할 수 있음
1. 의료진-환자 간의 대화 내용 음성 인식 서비스에 활용
- 음성 인식을 통해 생성되는 텍스트 정보를 EMR에 작성할 수 있는 고도화 모델로 사용할 수 있음
2) 진료 프로세스 분류모델
● 모델 학습
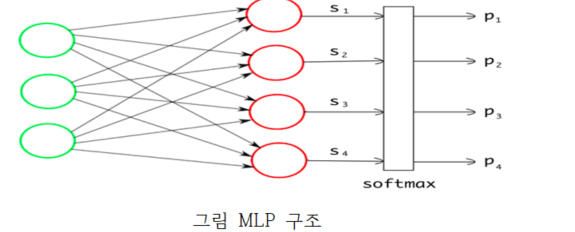
4가지 프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실)로 분류되어 전사된 텍스트를 전처리 후 MLP 구조에 데이터 학습을 통해서 Multi Class Classification을 할 수 있는 모델을 개발
| 학습 | 검증 | 시험 | |
|---|---|---|---|
| 개요 | MLP 아키텍쳐를 통해 학습 | 학습 도중 모델 성과 평가 및 비교 | 모델 학습 완료 후 모델 테스트 |
| Accuracy 점수 등 | |||
| 학습 데이터 | 4195례 | 525례 | 524례 |
● 서비스 활용 시나리오
음성 인식으로 생성된 텍스트를 4가지 프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실)로 구분하여 텍스트 분류
1. 의료진-환자 간의 대화 내용 분류 서비스에 활용
- 음성 인식을 통해 생성되는 텍스트 정보를 내용에 따라 4가지 프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실로 구분하여 EMR에 작성할 수 있는 고도화 모델로
그림 MLP 구조
사용할 수 있음
데이터 포맷
1) 원문데이터 포맷
응급실 임상 대화 데이터 : WAV
음성 전사 및 메타 데이터 : JSON
| 구분 | 획득(수집)단계 | 정제 단계 | 가공(라벨링) 단계 |
|---|---|---|---|
| 데이터 구분 | 원시데이터 | 원천데이터 | 최종데이터 |
| 데이터 형태 | WAV | WAV, JSON | WAV, JSON |
| 데이터 포맷 | 16kHz sampling rate, 16bit, mono 방식으로 인코딩 | 16kHz sampling rate, 16bit, mono 형식의 데이터 |
데이터 구성
어노테이션 포맷
| No. | 항목 | 타입 | 필수여부 | |
|---|---|---|---|---|
| 영문명 | 한글명 | |||
| dataset | object | |||
| 1 | date | 녹음 일자 | string | Y |
| 2 | category | 프로세스 목록 | string | Y |
| 3 | ktas | KTAS 등급 | number | Y |
| 4 | patient | 환자 정보 | object | Y |
| 4-1 | patient_age | 환자 나이대 | string | Y |
| 4-2 | patient_gender | 환자 성별 | string | Y |
| 4-3 | medical_history | 과거력 | string | |
| 5 | speaker | 화자 정보 | array | |
| 5-1 | id | 화자 아이디 | string | Y |
| 5-2 | role | 역할 | string | Y |
| 5-3 | gender | 화자 성별 | string | Y |
| 6 | treatment | 처치 정보 | object | Y |
| 6-1 | diseases_type | 질병분류 | string | Y |
| 6-2 | diagnosis | 진단명 | string | Y |
| 6-3 | exam_treatment | 치료 및 검사 | string | Y |
| 7 | annotations | 어노테이션 목록 | array | |
| 7-1 | id | 화자 아이디 | string | Y |
| 7-2 | form | 전사, 라벨링 결과 | string | Y |
| 7-3 | original_form | 철자 전사 내용 | string | Y |
| 7-4 | annotations_form | 어노테이션 전사 내용 | String | Y |
| 7-5 | annotation_list | 어노테이션 리스트 | String | Y |
| 7-5 | start | 발화 시작 시간 (소수점 3자리까지) | number | Y |
| 7-7 | end | 발화 종료 시간 (소수점 3자리까지) | number |
|
실제 예시
{
"dataset": {
"date": 220710,
"category": "초진",
"ktas": 4,
},
"speaker": [
{
"id": 1,
"age": "40대",
"gender": "남성",
"role": "의사",
},
{
"id": 2,
"age": "30대",
"gender": "여성",
"role": "환자",
}
],
"annotations": [
{
"id": 1,
"form": "어디가 안 좋으신가요",
"original_form": "어디가 안 좋으신가요",
"annotations_form": "null",
"start": "0.00",
"end": "2.39",
"annotations_List": "null",
},
{
"id": 2,
"form": "(삼 일)/(3일) 전부터 (@당뇨) 때문에 몸이 안 좋아서요",
"original_form": "삼 일 전부터 당뇨 때문에 몸이 안 좋아서요",
"annotations_form": "3일 전부터 당뇨 때문에 몸이 안 좋아서요",
"start": "2.39",
"end": "5.89",
"annotations_List": [
{
"annotations_id": 1,
"annotations_word": "당뇨",
}
]
},
],
"treatment": {
"depart": 내과,
"medical_history": "당뇨",
"exam_treatment": NULL,
},
}
데이터셋 구축 담당자
수행기관(주관) : ㈜타이거컴퍼니
| 책임자명 | 전화번호 | 대표이메일 | 담당업무 |
|---|---|---|---|
| 김범진 | 1688-3708 | tiger@tigrison.com | 사업총괄, 사업 인프라 제공, AI 모델 구축 및 검증, 클라우드 소싱 |
수행기관(참여)
| 기관명 | 담당업무 |
|---|---|
| 고려대학교 산학협력단 | 데이터 수집, 데이터 검증 |
| 길의료재단 | AI 모델 구축 및 검증 |
| 비투엔 | 품질관리 |
| 소리자바 | 음성 데이터 정제 및 전사, 학습데이터 구축, 음성 데이터 가공, 학습데이터 검증,클라우드 소싱 |
| 디그랩 | 음성 데이터 정제 및 전사, 학습데이터 구축, 음성 데이터 가공, 학습데이터 검증,클라우드 소싱 |
데이터 관련 문의처
| 담당자명 | 전화번호 | 이메일 |
|---|---|---|
| 김정식 | 1688-3708 | winkjs@tigrison.com |