공공 의료데이터 상세

구음장애인 명령어 데이터
데이터 변경이력
| 버전 | 일자 | 변경내용 | 비고 |
|---|---|---|---|
| 1.1 | 2023-11-17 | 데이터 최종 개방 | |
| 1.0 | 2023-05-26 | 데이터 개방 | Beta Version |
데이터 히스토리
| 일자 | 변경내용 | 비고 |
|---|---|---|
| 2025-09-05 | 데이터셋 변경 | 구축업체정보 수정 |
| 2025-05-08 | 데이터셋 변경 | 구축업체정보 수정 |
| 2025-01-06 | 데이터셋 변경 | 메타데이터 데이터 구축량 정보 수정 |
| 2023-12-20 | 산출물 최종 공개 |
소개
구음장애를 가진(뇌경색, 뇌출혈, 루게릭, 청각장애) 사람을 대상으로 13가지 주제를 기반으로 한 명령어(일상, 금융, 엔터, 교통정보 등)를 녹음한 음성데이터
구축목적
구음장애를 가진(뇌경색, 뇌출혈, 루게릭, 청각장애) 사람을 대상으로 13가지 주제를 기반으로 한 명령어(일상, 금융, 엔터, 교통정보 등)를 녹음한 음성데이터를 통해 뇌졸중을 분류 AI 활용 모델을 만들기 위한 목적으로 구축
| 데이터 영역 | 헬스케어 | 데이터 유형 | 오디오 |
|---|---|---|---|
| 데이터 형식 | WAV | 데이터 출처 | 이화여자대학교산학협력단, 충남대학교 산학협력단, ㈜청각장애인생애지원센터, 동남권원자력의학원, 경희대학교 산학협력단 |
| 라벨링 유형 | 전사(음성) | 라벨링 형식 | JSON |
| 데이터 활용 서비스 | 구음장애인 명령어 음성인식 서비스 | 데이터 구축년도/ 데이터 구축량 |
2022년/2,976,962 |
데이터 통계
1) 데이터 구축 규모
| 데이터 종류 | 데이터 항목 | 데이터 형식 | 카테고리 분류 | 데이터 수 |
|---|---|---|---|---|
| 구음장애인 명령어 데이터데이터 | 원천 데이터 | WAV | 뇌경색 | 867,343건 |
| 뇌출혈 | 6,039건 | |||
| 루게릭 | 203건 | |||
| 청각장애 | 2,102,837건 | |||
| 합계 | 2,976,422 | |||
| 라벨링 데이터 | JSON | 뇌경색 | 867,343건 | |
| 뇌출혈 | 6,039건 | |||
| 루게릭 | 203건 | |||
| 청각장애 | 2,102,837건 | |||
| 합계 | 2,976,422 |
2) 데이터 분포
가. 중증도 분포
| 카테고리 구분 | 데이터 수 | 비율 |
|---|---|---|
| 뇌경색 | 867,343건 | 29.14% |
| 뇌출혈 | 6,039건 | 0.20% |
| 루게릭 | 203건 | 0.01% |
| 청각장애 | 2,102,837건 | 70.65 |
| 합계 | 2,976,422 | 100% |
나. 성별
| 카테고리 구분 | 수 | 비율 |
|---|---|---|
| 여성 | 1,605,423 | 53.94% |
| 남성 | 1,370,999 | 46.06% |
| 합계 | 2,976,422 | 100% |
활용 모델
1) 음성 인식 모델
● 모델 학습
Librosa를 통해 수집된 음성 데이터를 학습모델에 사용할 수 있도록 20초 미만의 음성으로 slicing을 통해 전처리 수행
전처리된 음성 데이터를 ESPNet 모델에 학습하여 명령어 음성 데이터를 인식하는 음성 인식 모델을 개발
| 학습 | 검증 | 시험 | |
|---|---|---|---|
| 개요 | ESPNet 학습 | 학습 도중 모델 성과 평가 및 비교 | 모델 학습 완료 후 모델 테스트 |
| CER 점수 등 | |||
| 학습 데이터 | 2,974,422건 | 2,974,422건 | 2,974,422건 |
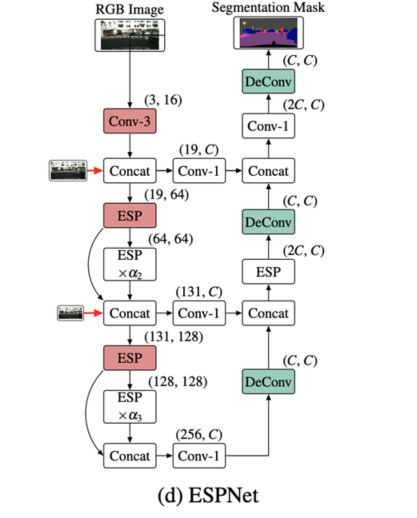
● 서비스 활용 시나리오
구축한 모델은 구음장애를 가진 사람의 대화를 인식하는 서비스에 활용할 수 있음
1. 구음장애인 명령어를 인식하는 음성인식 서비스에 활용
2) 뇌졸중 분류 모델
● 모델 학습
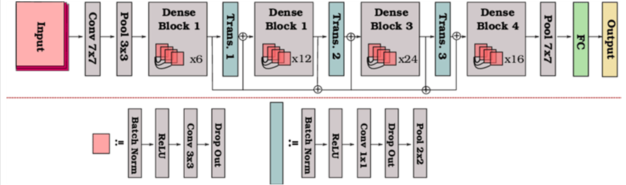
뇌경색, 뇌출혈, 루게릭, 청각장애를 가진 사람의 음성을 학습하여 뇌졸중을 가진 사람을 분류하는 분류 모델을 개발
| 학습 | 검증 | 시험 | |
|---|---|---|---|
| 개요 | mobile + dense 아키텍쳐를 통해 학습 | 학습 도중 모델 성과 평가 및 비교 | 모델 학습 완료 후 모델 테스트 |
| F-1 Score점수 등 | |||
| 학습 데이터 | 2,974,422건 | 2,974,422건 | 2,974,422건 |
● 서비스 활용 시나리오
음성 인식으로 생성된 텍스트를 4가지 프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실)로 구분하여 텍스트 분류
1. 의료진-환자 간의 대화 내용 분류 서비스에 활용
- 음성 인식을 통해 생성되는 텍스트 정보를 내용에 따라 4가지 프로세스(예진, 초진, 투약 및 검사, 검사결과설명 및 퇴실로 구분하여 EMR에 작성할 수 있는 고도화 모델로 사용할 수 있음
데이터 포맷
1) 원문데이터 포맷
구음장애인 명령어 데이터 : WAV
음성 전사 및 메타 데이터 : JSON
| 구분 | 획득(수집)단계 | 정제 단계 | 가공(라벨링) 단계 |
|---|---|---|---|
| 데이터 구분 | 원시데이터 | 원천데이터 | 최종데이터 |
| 데이터 형태 | WAV | WAV, JSON | WAV, JSON |
| 데이터 포맷 | 16kHz sampling rate, 16bit, mono 방식으로 인코딩 | 16kHz sampling rate, 16bit, mono 형식의 데이터 |
구음장애인 명령어 데이터 구조 예시
데이터 구성
| 원천데이터 | Train | 뇌경색 | IoT |
|---|---|---|---|
| Test | 뇌출혈 | 일상 | |
| Validation | 루게릭 | 금융 | |
| 청각장애 | 엔터테인먼트 | ||
| 교통정보 | |||
| 의료시설정보 | |||
| 의료예약 | |||
| 일반의료정보 | |||
| 날씨 | |||
| 장애편의 | |||
| 일반정보검색 | |||
| 쇼핑 | |||
| 장애지원센터 |
원천데이터는 3분할 Train, Test, Validation으로 구성
각 Train, Test, Validation 폴더에는 4개의 하위폴더 뇌경색, 뇌출혈, 루게릭, 청각장애로 구성되고 다음 하위 폴더에는 13개의 명령어 종류에 대한 폴더로 구성되어 있음
어노테이션 포맷
| No. | 항목 | 타입 | 필수여부 | |
|---|---|---|---|---|
| 영문명 | 한글명 | |||
| 1 | dataset | 데이터셋 정보 | object | Y |
| 1-1 | filename | 파일명 | string | Y |
| 1-2 | speakerID | 화자 아이디 | string | Y |
| 1-3 | sentenceType | 문장 종류 | string | Y |
| 1-4 | category | 명령어 카테고리 | string | |
| 1-5 | numberOfRecordings | 녹음 횟수 | string | Y |
| 1-6 | sentenceID | 문장 아이디 | string | Y |
| 1-7 | recordingSystem | 녹음 방식 | string | Y |
| 1-8 | recordingQuality | 녹음 형태 | string | Y |
| 1-9 | recordingDate | 녹음 날짜 | string | Y |
| 1-10 | recordingTime | 녹음 시간 (소수점 세 자리까지) | number | Y |
| 1-11 | recordingDevice | 녹음 기기 | string | Y |
| 2 | speaker | 발화자 정보 | array | Y |
| 2-1 | gender | 성별 | string | Y |
| 2-2 | age | 연령대 | string | Y |
| 2-3 | education | 교육력 | string | Y |
| 2-4 | hospital | 병원 | string | Y |
| 2-5 | classification | 장애분류 | string | Y |
| 2-6 | intelligibility | 말명료도 | string | Y |
| 2-7 | degree | 장애정도 | string | Y |
| 2-8 | diagnostics | 최근진단일 | string | |
| 2-9 | device | 청각보조기기 사용유무 | string | |
| 2-10 | deviceUsedAge | 청각보조기기 착용시기 | string | |
| 2-11 | comunicationTool | 주의사소통수단 | string | |
| 2-12 | rehabilitation | 재활경험 | string | |
| 2-13 | hearingLoss | 청력손실시기 | string | |
| 3 | annotations | 전사 정보 | array | |
| 3-1 | script | 명령어 스크립트 | string | |
| 3-2 | form | 발음/철자 전사 | string | Y |
| 3-3 | pronunciationForm | 발음 전사 | string | |
| 3-4 | spellingForm | 철자 전사 | string | Y |
| 3-5 | start | 발화 시작 시간 (소수점 세 자리까지) | number | Y |
| 3-6 | end | 발화 종료 시간 (소수점 세 자리까지) | number | Y |
{
"dataset": {
"filename": "HM0001_SCO_A_1_001",
"speakerID": "HM0001",
"sentenceType": "SCO",
"category": "A",
"numberOfRecordings": "1",
"sentenceID": "001",
"recordingSystem": "CON",
"recordingQuality": "16000Hz",
"recordingDate": "20220729",
"recordingTime": 3.714,
"recordingDevice": "SM"
},
"speaker": {
"gender": "M",
"age": "50~60대",
"education": "E4",
"hospital": "HM",
"classification": "CI",
"intelligibility": "SIR3",
"degree": "SEVERE",
"diagnostics": "20220723",
"device": null,
"deviceUsedAge": null,
"comunicationTool": null,
"rehabilitation": null,
"hearingLoss": null
},
"annotations": {
"script": "외출할 때 티브이 꺼 줘.",
"form": "(애츨할)/(외출할) 때 티브이 꺼 (즈어.)/(줘.)",
"pronunciationForm": "애츨할 때 티브이 꺼 즈어.",
"spellingForm": "외출할 때 티브이 꺼 줘.",
"start": 0.000,
"end": 3.714
}
}
데이터셋 구축 담당자
수행기관(주관) : ㈜타이거컴퍼니
| 책임자명 | 전화번호 | 대표이메일 | 담당업무 |
|---|---|---|---|
| 김범진 | 1688-3708 | tiger@tigrison.com | 사업총괄, 사업 인프라 제공, AI 모델 구축 및 검증, 크라우드 소싱 |
수행기관(참여)
| 기관명 | 담당업무 |
|---|---|
| 이화여자대학교산학협력단, | 데이터 수집 |
| 충남대학교 산학협력단 | 데이터 수집 |
| ㈜청각장애인생애지원센터 | 데이터 수집 |
| 동남권원자력의학원 | 데이터 수집 |
| 경희대학교 산학협력단 | 데이터 수집 |
| 소리자바 | 음성 데이터 정제 및 전사, 학습데이터 구축, 음성 데이터 가공, 학습데이터 검증, 크라우드 소싱, AI 모델 구축 및 검증 |
| 디그랩 | 음성 데이터 정제 및 전사, 학습데이터 구축, 음성 데이터 가공, 학습데이터 검증, 크라우드 소싱 |
| 비투엔 | 품질 관리 |
| 길의료재단 | AI 모델 구축 및 검증 |
| 하이 | 음성 수집 가이드라인 수립, 음성데이터 전사규칙 및 매뉴얼 마련 |
| 한국교통대학교 산학협력단 | 가공공정 품질관리, 홍보 |
데이터 관련 문의처
| 담당자명 | 전화번호 | 이메일 |
|---|---|---|
| 김정식 | 1688-3708 | winkjs@tigrison.com |